GitHub
Projets open source couvrant le deep learning, les chatbots IA en langues africaines, la visualisation NLP et la bibliothèque Python publiée sur PyPI.
Wolof culture chatbot
Chatbot IA conversationnel en langue wolof, proof-of-concept fonctionnel d'un agent dialogue dans une langue nationale africaine à faibles ressources numériques.
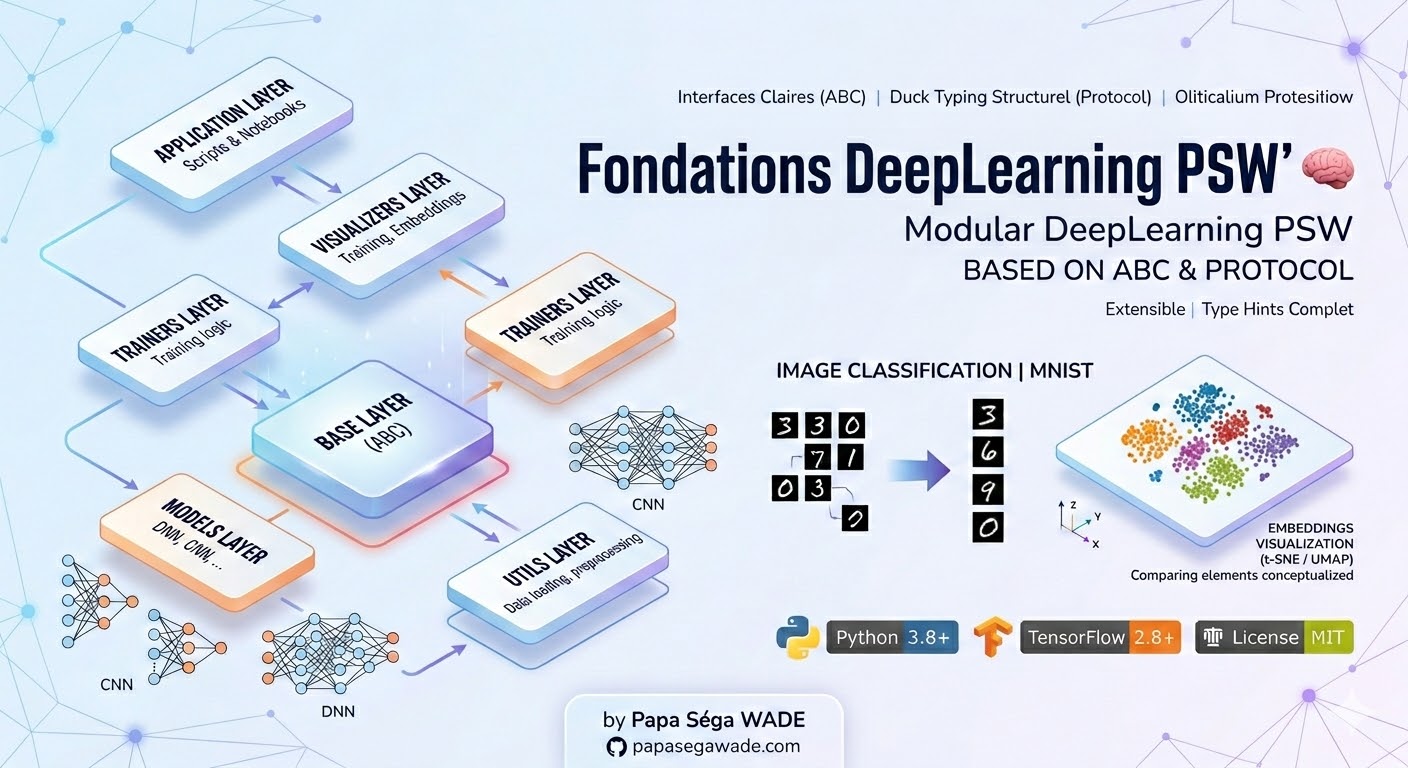
Fondations DeepLearning PSW
Collection de notebooks Jupyter pour l'apprentissage du Deep Learning, CNNs, RNNs, Transformers, MNIST, CIFAR-10. Ressource pédagogique partagée avec la communauté.

Claude Code Best Practice Playbook
Guide de meilleures pratiques pour optimiser l'utilisation de Claude Code : structuration des hooks, gestion du contexte, patterns de sous-agents parallèles et réduction drastique des coûts en tokens.

Claude Code Token Optimization
Système de hooks Claude Code qui réduit la consommation de tokens de 285M à 50M (-82%) par session : rejet des lectures de fichiers volumineux, interception intelligente des outils et monitoring du budget en temps réel.
text2mapviewer
Bibliothèque Python publiée sur PyPI permettant de visualiser des textes géolocalisés sur des cartes interactives. Idéal pour l'analyse géospatiale de corpus NLP.
ollama_chatpdf_llama3
Système RAG local avec Ollama + LLaMA 3 pour interroger des documents PDF en langage naturel, entièrement offline, sans API cloud.